在现代软件开发中,处理和分析各种类型的文档文件是一个常见的任务。Apache Tika作为一个开源的Java库,提供了强大的文档内容解析功能,能够帮助开发者从各种文件中提取文本内容,无论是PDF、Word文档、Excel表格还是其他格式的文件。
配置Apache Tika依赖
首先,在你的Java项目中,需要引入Apache Tika核心库和标准解析器包的依赖:
<!-- Apache Tika 依赖项 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>2.6.0</version>
</dependency>
确保你的项目构建工具(如Maven或Gradle)能够正确解析并下载这些依赖。
使用Apache Tika解析文档内容
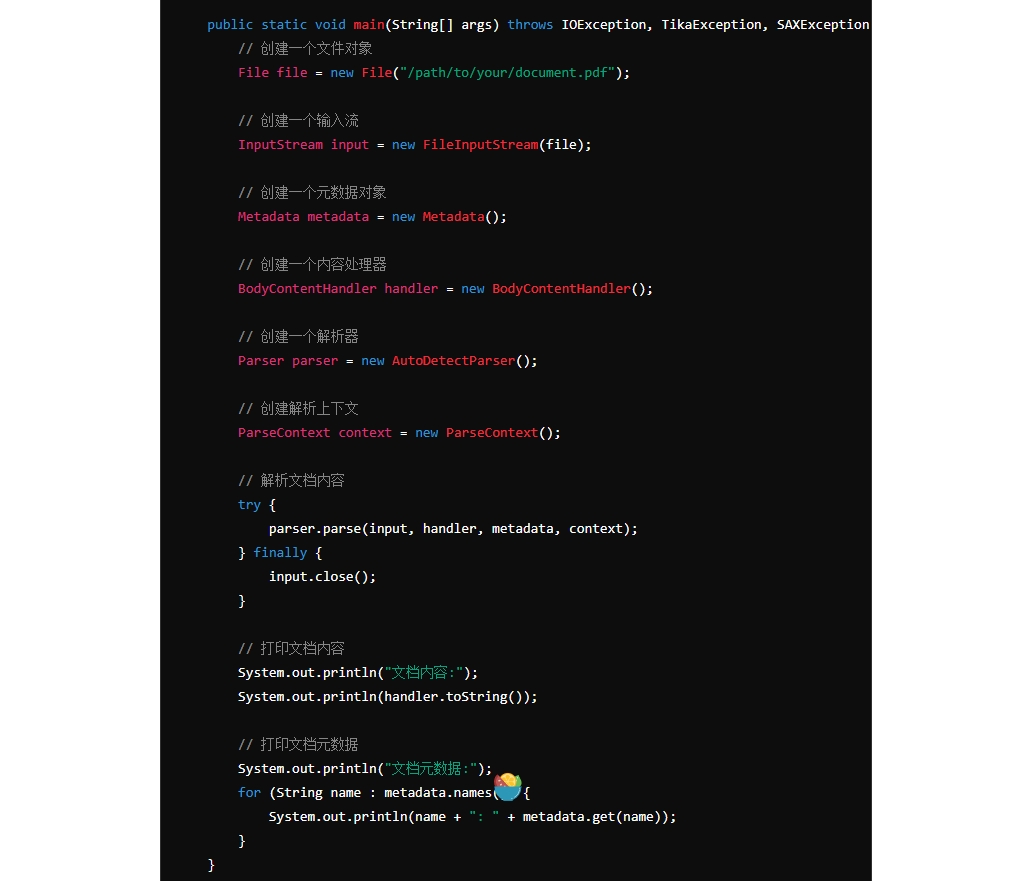
Apache Tika提供了简单而强大的API来处理文档内容解析任务。以下是一个基本的示例展示如何使用Apache Tika从一个PDF文件中提取文本内容:
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.xml.sax.SAXException;
public class DocumentParsingExample {
public static void main(String[] args) throws IOException, TikaException, SAXException {
// 创建一个文件对象
File file = new File("/path/to/your/document.pdf");
// 创建一个输入流
InputStream input = new FileInputStream(file);
// 创建一个元数据对象
Metadata metadata = new Metadata();
// 创建一个内容处理器
BodyContentHandler handler = new BodyContentHandler();
// 创建一个解析器
Parser parser = new AutoDetectParser();
// 创建解析上下文
ParseContext context = new ParseContext();
// 解析文档内容
try {
parser.parse(input, handler, metadata, context);
} finally {
input.close();
}
// 打印文档内容
System.out.println("文档内容:");
System.out.println(handler.toString());
// 打印文档元数据
System.out.println("文档元数据:");
for (String name : metadata.names()) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
实际应用场景
以上示例展示了如何使用Apache Tika从一个PDF文件中提取文本内容,并获取文档的元数据信息。在实际应用中,你可以根据需要扩展和优化这些功能,例如批量处理多种格式的文档、文档内容分析、信息提取等。
总结
你学习了如何在Java开发中利用Apache Tika库实现文档内容的解析和提取。合理配置依赖、实现基本的文档解析功能,并结合具体应用场景,能够帮助你轻松处理各种文档文件,并提取其中的关键信息。

发表评论 取消回复